From a blog post Andrew Gelman made over a decade ago that I first came across about five or six years ago (http://andrewgelman.com/2004/12/29/type_1_type_2_t/):
In statistics, we learn about Type 1 and Type 2 errors. For example, from an intro stat book:
- A Type 1 error is committed if we reject the null hypothesis when it is true.
- A Type 2 error is committed if we accept the null hypothesis when it is false.
That’s a standard definition that anyone who’s had a basic statistics course has probably heard (even if they’ve forgotten it by now). Gelman points out, however, that it is arguably more useful to think about two different kinds of error,
- Type S errors occur when you claim that an effect is positive even though it’s actually negative.
- Type M errors occur when you claim that an effect is large when it’s really small (or vice versa).
You’re probably thinking to yourself, “Why should I care about Type S or Type M errors? Surely if I do a typical null hypothesis test and reject the null hypothesis, I won’t make a Type S error, right?”1 Wrong! More precisely, you’re wrong if your sample size is small, and your data are noisy.
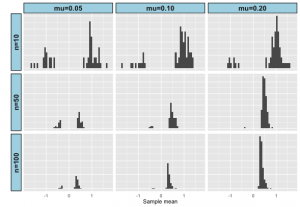
Let me illustrate this with a really simple example. Suppose we’re comparing the mean of two different populations x and y. To make that comparison, we take a sample of size N from each population, and perform a t-test (assuming equal variances in x and y). To make this concrete let’s assume that the variance is 1 in both populations and that the mean in population y is 0.05 greater than the mean in population x and suppose that N = 10. Now you’re probably thinking that the chances of detecting a difference between x and y isn’t great, and you’d be right. In fact, in the simulation below only 50 out of 1000 had a P-value < 0.05. What may surprise you is that of those 50 samples with P < 0.05, the mean of the sample from x was smaller than the mean of the sample from y. In other words, more than 30% of the time we would have made the wrong conclusion about which population had the larger mean, even though the difference in our sample was statistically significant. With a sample size of 100, we don’t pick up a significant difference between x and y that much more often (66 out of 1000 instead of 50 out of 1000), but only 9 of the 66 samples has the wrong sign. Obviously, if the difference in means is greater, sample size is less of an issue, but the bottom line is this:
If you are studying effects where between group differences are small relative to within group variation, you need a large sample to be confident in the sign of any effect you detect, even if the effect is statistically significant.
The figure below illustrates results for 1000 replicates drawn from two different populations with the specified difference in means and sample sizes. Source code (in R) to replicate the results and explore different combinations of sample size and mean difference is available in Github: https://github.com/kholsinger/noisy-data.
Gelman and Carlin (Perspectives on Psychological Science 9:641; 2014 http://dx.doi.org/10.1177/1745691614551642) provide a lot more detail and useful advice, including this telling paragraph from the conclusions:
[W]e believe that too many small studies are done and preferentially published when “significant.” There is a common misconception that if you happen to obtain statistical significance with low power, then you have achieved a particularly impressive feat, obtaining scientific success under difficult conditions.
Bottom line: Be wary of results from studies with small sample sizes, even if the effects are statistically significant.
1I’m not going to talk about Type M errors, because in my work I’m usually happy just determining whether or not a given effect is positive and less worried about whether it’s big or small. If you’re worried about Type M errors, read the paper by Gelman and Tuerlinckx (PDF).

