So far in this course, we’ve focused on describing the pattern of variation within and among populations. We’ve talked about inbreeding, which causes genotype frequencies to change, although it leaves allele frequencies the same, and we’ve talked about how to describe variation among populations. But we haven’t yet discussed any evolutionary processes that could lead to a change in allele frequencies within populations.1
Let’s return for a moment to the list of assumptions we developed when we derived the Hardy-Weinberg principle and see what we’ve done so far.
Genotype frequencies are the same in males and females, e.g.,
Genotypes mate at random with respect to their genotype at this particular locus.
Meiosis is fair. More specifically, we assume that there is no segregation distortion, no gamete competition, no differences in the developmental ability of eggs, or the fertilization ability of sperm.
There is no input of new genetic material, i.e., gametes are produced without mutation, and all offspring are produced from the union of gametes within this population.
The population is of infinite size so that the actual frequency of matings is equal to their expected frequency and the actual frequency of offspring from each mating is equal to the Mendelian expectations.
All matings produce the same number of offspring, on average.
Generations do not overlap.
There are no differences among genotypes in the probability of survival.
The only assumption we’ve violated so far is Assumption #2, the random-mating assumption. We’re going to spend the next several lectures talking about what happens when you violate Assumption #3, #6, or #8. When any one of those assumptions is violated we have some form of natural selection going on.2
Depending on which of those three assumptions is violated and how it’s violated we recognize that selection may happen in different ways and at different life-cycle stages.3
Meiosis is fair. There are at least two ways in which this assumption may be violated.
Segregation distortion: The two alleles are
not equally frequent in gametes produced by heterozygotes. The
Gamete competition: Gametes may be produced in equal frequency in heterozygotes, but there may be competition among them to produce fertilized zygotes, e.g., sperm competition in animals, pollen competition in seed plants.4
All matings produce the same number of progeny.
Fertility selection: The number of offspring produced may depend on maternal genotype (fecundity selection), paternal genotype (virility selection), or on both.
Survival does not depend on genotype.
Viability selection: The probability of survival from zygote to adult may depend on genotype, and it may differ between sexes.
At this point you’re probably thinking that I’ve covered all the possibilities. But by now you should also know me well enough to guess from the way I wrote that last sentence that if that’s what you were thinking, you’d be wrong. There’s one more way in which selection can happen that corresponds to violating
Individuals mate at random.
Sexual selection: Some individuals may be more successful at finding mates than others. Since females are typically the limiting sex (Bateman’s principle), the differences typically arise either as a result of male-male competition or female choice.
Disassortative mating: When individuals preferentially choose mates different from themselves, rare genotypes are favored relative to common genotypes. This leads to a form a frequency-dependent selection.
That’s a pretty exhaustive (and exhausting) list of the ways in which selection can happen. We could spend the entire semester exploring each of those, but we’re going to focus in detail only on viability selection. Although I will say only a little about other forms of selection, it’s important to remember that any or all of the other forms of selection may be operating simultaneously on the genes or the traits that we’re studying, and the direction of selection due to these other components may be the same or different from the direction of viability selection. Remembering this is particularly important because there’s a tendency to think that viability selection is the only kind of natural selection there is.
We’re going to focus on viability selection for two reasons:
The most basic properties of natural selection acting on other components of the life history are similar to those of viability selection. A good understanding of viability selection provides a solid foundation for understanding other types of selection.5
The algebra associated with understanding viability selection is a lot simpler than the algebra associated with understanding any other type of selection, and the dynamics are simpler and easier to understand.6
To understand the basics, we’ll start with a numerical example using
some data on Drosophila pseudoobscura that
Theodosius Dobzhansky collected more than 70 years ago. You may remember
that this species has chromosome inversion polymorphisms. Although these
inversions involve many genes, they are inherited as if they were single
Mendelian loci, so we can treat the karyotypes as single-locus genotypes
and study their evolutionary dynamics. We’ll be considering two
inversion types: the Standard inversion type,
| Symbol | Definition |
|---|---|
| number of individuals in the population | |
| frequency of |
|
| frequency of |
|
| frequency of |
|
| fitness of |
|
| fitness of |
|
| fitness of |
The data look like this:7
| Genotype | |||
|---|---|---|---|
| Number in eggs | 41 | 82 | 27 |
| viability | 0.6 | 0.9 | 0.45 |
| Number in adults | 25 | 74 | 12 |
It should be easy for you by this time to calculate the genotype frequencies in eggs and adults.8 I’ll refer to genotype frequencies in eggs (or newly-formed zygotes) as genotype frequencies before selection and genotype frequencies in adults as genotype frequencies after selection.
If you followed that, you shouldn’t have much trouble following how to calculate the allele frequencies before and after selection:
If you’re still awake, you’re probably wondering9 why
I was able to substitute
Let’s stare at the selection equation for awhile and see what it
means.
| Fitnesses | |||
| Equation | |||
| [eq:absolute] | |||
| [eq:relative] | 1 | ||
| 1 | |||
| 1 | |||
These observations illustrate the following general principle:
The consequences of natural selection (in an infinite population) depend only on the relative magnitude of fitnesses, not on their absolute magnitude.
That means, for example, that in order to predict the outcome of viability selection, we don’t have to know the probability that each genotype will survive, i.e., their absolute viabilities. We only need to know the probability that each genotype will survive relative to the probability that other genotypes will survive, i.e., their relative viabilities. As we’ll see later, it’s sometimes easier to estimate the relative viabilities than to estimate absolute viabilities.12
In case you haven’t already noticed, there’s almost always more than
one way to write an equation.13 They’re all
mathematically equivalent, but they emphasize different things. In this
case, it can be instructive to look at the difference in allele
frequencies from one generation to the next,
Why do we care? Because it provides some (relatively obvious)
intuition on how allele frequencies will change from one generation to
the next. If
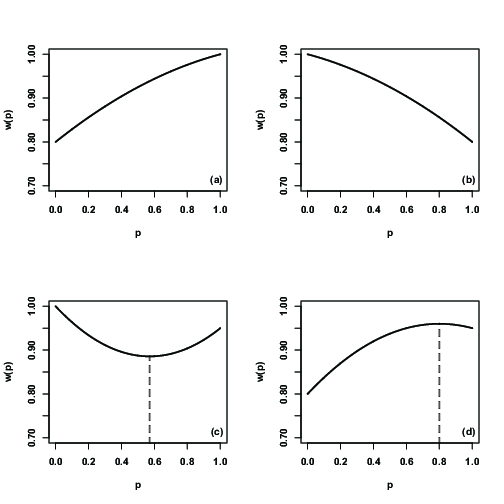
Well, all that algebra was lots of fun,15 but what good did it do us? Not an enormous amount, except that it shows us (not surprisingly), that allele frequencies are likely to change as a result of viability selection, and it gives us a nice little formula we could plug into a computer to figure out exactly how. One of the reasons that it’s useful16 to go through all of that algebra is that it allows us to make predictions about the consequences of natural selection simply by knowing the pattern of viability differences. What do I mean by pattern? Funny you should ask (Table 1).
| Pattern | Description |
|---|---|
| Directional | |
| or | |
| Disruptive | |
| Stabiliizing |
Before exploring the consequences of these different patterns of
natural selection, I need to introduce you to a very important result:
Fisher’s Fundamental Theorem of Natural Selection. We’ll go through the
details later when we get to quantitative genetics. In fact, we’ll
derive Fisher’s Fundamental Theorem for one locus and two alleles. For
now all you need to know is that viability selection causes the mean
fitness of the progeny generation to be greater than or equal to the
mean fitness of the parental generation, with equality only at
equilibrium, i.e.,
To use the Fundamental Theorem we plot
If we plot
Let’s explore this example a little further. To do so, I’m going to
set
Fisher’s Fundamental Theorem tells us which of these equilibria
matter. I’ve already mentioned that depending on which side of the bowl
you start, you’ll either lose the
Well, if you start exactly there, you’ll stay there forever (in an infinite population). But if you start ever so slightly off the equilibrium, you’ll move farther and farther away. It’s what mathematicians call an unstable equilibrium. Any departure from that equilibrium gets larger and larger. For evolutionary purposes, we don’t have to worry about a population getting to an unstable equilibrium. It never will. Unstable equilibria are ones that populations evolve away from.
When a population has only one allele present it is said to be fixed for that allele. Since having only one allele is also an equilibrium (in the absence of mutation), we can also call it a monomorphic equilibrium. When a population has more than one allele present, it is said to be polymorphic. If two or more alleles are present at an equilibrium, we can call it a polymorphic equilibrium. Thus, another way to describe the results of disruptive selection is to say that the monomorphic equilibria are stable, but that the polymorphic equilibrium is not.22
If we plot
In this case we can see that no matter what allele frequency the
population starts with, the only way that
So far we’ve been talking about natural selection that occurs as a result of differences in the probability of survival, i.e., viability selection. There are, of course, other ways in which natural selection can occur:
Heterozygotes may produce gametes in unequal frequencies, segregation distortion, or gametes may differ in their ability to participate in fertilization, gametic selection.25
Some genotypes may be more successful in finding mates than others, sexual selection.
The number of offspring produced by a mating may depend on maternal and paternal genotypes, fertility selection.
In fact, most studies that have measured components of selection have identified far larger differences due to fertility than to viability. Thus, fertility selection is a very important component of natural selection in most populations of plants and animals. As we’ll see a little later, it turns out that sexual selection is mathematically equivalent to a particular type of fertility selection. But before we get to that, let’s look carefully at the mechanics of fertility selection.
It is useful to describe patterns of fertility selection in terms of a fitness matrix. Describing the matrix is easy. Writing it down gets messy. Each element in the table is simply the average number of offspring produced by a given mated pair. We write down the table with paternal genotypes in columns and maternal genotypes in rows:
| Paternal genotype | |||
| Maternal genotype | |||
Then the frequency of genotype
It probably won’t surprise you to learn that it’s very difficult to say anything very general about how genotype frequenices will change when there’s fertility selection. Not only are there nine different fitness parameters to worry about, but since genotypes are never guaranteed to be in Hardy-Weinberg proportion, all of the algebra has to be done on a system of three simultaneous equations.28 There are three weird properties that I’ll mention:
A high fertility of heterozygote
Selection may prevent loss of either allele, but there may be no stable equilibria.
There is one case in which it’s fairly easy to understand the
consequences of selection, and that’s when one of the two alleles is
very rare. Suppose, for example, that
Conditions ([eq:a-1]) and ([eq:a-2]) are fairly easy to interpret intuitively: There is a protected polymorphism if the average fecundity of matings involving a heterozygote and the “resident” homozygote exceeds that of matings of the resident homozygote with itself.31
NOTE: It’s entirely possible for neither inequality to be satisfied and for their to be a stable polymorphism. In other words, depending on where a population starts, selection may eliminate one allele or the other or keep both segregating in the population in a stable polymorphism.32
These notes are licensed under the Creative Commons Attribution License. To view a copy of this license, visit or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA.